Memory decay in AI agents is the function that determines how a memory's relevance fades over time — and almost every production system gets it wrong by picking the simplest curve, applying it uniformly to every memory, and never tuning it. The result is an agent that either forgets important context too fast or keeps stale information around forever.
Vector search alone doesn't solve this. Cosine similarity tells you how semantically close a memory is to the query, not how recently it was relevant. Without a decay function, your agent will retrieve a year-old debugging note with the same confidence as yesterday's architecture decision. Both are similar to "how does our auth work?" — only one is current.
Most agent memory systems answer this with exponential decay. It's the textbook approach, and it's mathematically wrong for human-like memory. This post covers why exponential decay fails, why the power-law curve is empirically superior, and the engineering decisions that make decay actually useful in production.
Assumed audience: Engineers building persistent memory for AI agents who've already implemented vector search. If you've read our posts on episodic memory and consolidation, this is the layer that makes both work over long time horizons.
How Memory Decay Works in AI Agents
Decay is a multiplier on retrieval scores. Every memory has a base relevance score (typically cosine similarity to the query). The decay function multiplies that score by a value between 0 and 1, where 1 means "just stored" and 0 means "completely forgotten."
The general form:
final_score = semantic_similarity × decay(age, parameters)The choice of decay() is the entire game. The wrong function quietly degrades retrieval quality across every query. The right function preserves recent context, lets stale information fade, and matches the way humans actually forget — which matters because your agent is augmenting human reasoning, not replacing it.
Three decay functions show up in practice:
- Exponential decay:
e^(-age/S)where S is the decay scale - Power-law decay:
(1 + age/S)^(-c)where c is the exponent - Logarithmic compression (SIMPLE model): apply
log(1 + age)first, then any decay function
Each has different behavior at short, medium, and long timescales. The differences matter.
Why Exponential Decay Is the Default (And Why It's Wrong)
Exponential decay shows up in every introductory tutorial because the math is clean. Pick a half-life, plug it in, done. e^(-age/S) is monotonically decreasing, easy to compute, and produces sensible-looking output for short windows.
The problem appears at long timescales. Exponential decay drops sharply at first, then flattens to near-zero relatively quickly. With a 30-day decay scale, a 90-day-old memory retains roughly 5% of its score. A 180-day-old memory retains 0.25%. After six months, your agent has functionally forgotten everything that happened — even if some of those memories were genuinely important.
Hermann Ebbinghaus's 1885 forgetting curve experiments were originally fit with an exponential. For a century, that was the default model in memory research. But Ebbinghaus measured retention over hours and days, not weeks and months. When researchers extended the timescale, exponential stopped fitting the data.
Wickelgren (1972) and later Wixted & Ebbesen (1991) ran retention experiments across longer intervals and found something different: human memory follows a power-law curve, not an exponential one. The shape of forgetting is fundamentally different at scale.
The Power-Law Forgetting Curve
The power-law form is (1 + age/S)^(-c). The behavior is qualitatively different from exponential:
- Short term: drops fast — similar to exponential, sharp loss in the first hours and days
- Long term: drops slowly — the curve flattens but never collapses to zero the way exponential does
- Long tail: a 5-year-old memory retains a small but non-trivial fraction of its score
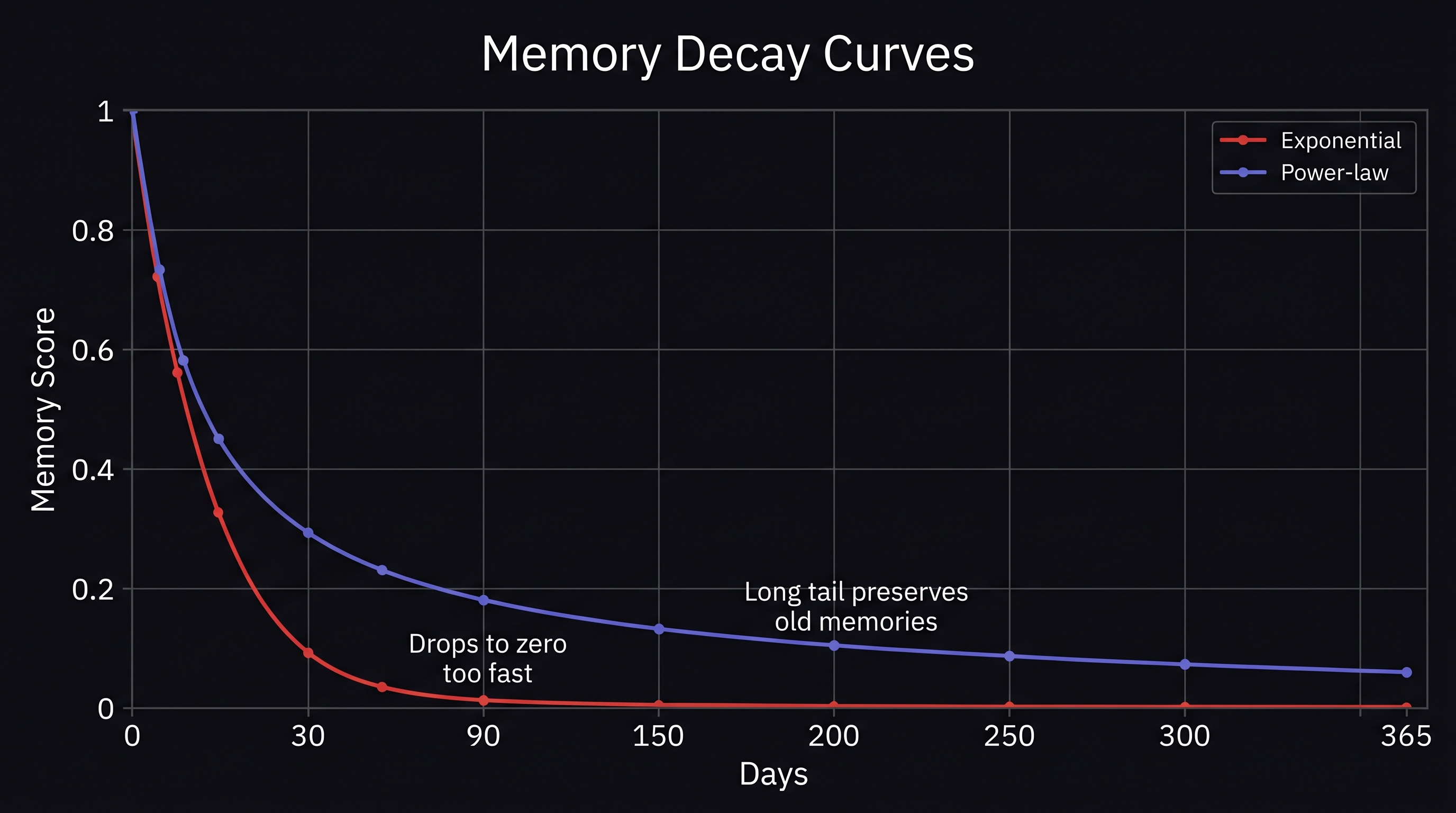
This matches everyday experience. You vividly remember an embarrassing moment from a decade ago but can't recall what you had for lunch on Tuesday. Recent low-importance events fade fast. Older significant events persist. Exponential decay can't reproduce this — its rate of forgetting is constant relative to the current score, so old and important looks the same as old and trivial.
Power-law decay is the model behind modern spaced repetition systems. FSRS (the algorithm powering Anki since 2023) uses a power-law forgetting function: R(t) = (1 + t / (9 × S))^(-1). The 9 × S denominator is calibrated so that retrievability hits 90% at the stability interval — a property that makes the math interpretable and the parameters tunable. Anki users repeat thousands of cards daily, and FSRS's predictions are validated against millions of real recall events. The empirical evidence is overwhelming: power-law is the curve that actually fits human memory.
For AI agents, this matters because the goal isn't to forget on a fixed schedule — it's to retrieve the right memory for the right query, regardless of whether the memory is from yesterday or six months ago. A power-law curve makes both possible. An exponential curve makes only one possible.
Stability vs. Retrievability: The Distinction Most Systems Miss
Here is the concept that distinguishes a serious memory decay implementation from a tutorial one. Stability and retrievability are not the same thing, and conflating them is why most agent memory systems struggle to handle long-running users.
FSRS treats them as separate quantities:
- Stability (S): the time interval at which retrievability drops to 90%. A property of the memory itself — how resistant it is to forgetting. Updated when the memory is accessed.
- Retrievability (R): the probability of successfully recalling the memory right now. A function of stability and elapsed time. Recomputed at every query.
- Difficulty (D): how inherently hard the memory is to retain, on a 1–10 scale. Some memories are structurally easier than others — short factual statements vs. complex multi-part reasoning.
Stability isn't fixed. Every time a memory is successfully retrieved, its stability increases — the memory becomes more resistant to future forgetting. This is why repeated exposure strengthens memory in humans, and why a memory of "user prefers dark mode" that gets retrieved 50 times across sessions decays much slower than a one-off memory accessed only once.
The counterintuitive part: harder recalls produce bigger stability gains. This is the "desirable difficulty" effect from cognitive science research (Robert Bjork, 1994). When a memory is on the edge of being forgotten and is retrieved successfully anyway, the stability gain is much larger than for an easy retrieval. This means an agent memory system should preferentially strengthen memories that were almost forgotten — those are the ones the user actually needed.
Most agent memory systems don't track stability at all. They use a single global decay rate for every memory, treating "user's coffee order from last week" the same as "user's authentication architecture from six months ago that they reference constantly." The result is uniform forgetting, which is just a slightly less wrong version of no decay at all.
Importance-Weighted Decay
A fixed decay rate, even with a good curve, is still wrong for one reason: not all memories are equally important. A memory the user explicitly flagged as critical shouldn't decay at the same rate as a casual aside.
The fix is importance-weighted decay. The decay rate becomes a function of the memory's importance score:
final_score = semantic_similarity × decay(age × (1 - importance), parameters)An importance score of 1.0 means no decay. An importance score of 0.0 means full decay at the configured rate. Real systems sit in between, with importance derived from three signals:
- Emotional weight — high absolute emotional valence increases importance. Strongly positive or negative interactions are more memorable in humans, and the same heuristic improves retrieval quality in agents.
- Explicit flagging — memories the user or application marks as important via API parameters or conversational signals.
- Retrieval frequency — memories retrieved often in past queries accumulate a stability boost over time. This is the FSRS-inspired component, and it's the one that makes the system improve with use rather than degrade.
This combination produces a system where important, frequently-accessed, emotionally-loaded memories persist for years, while one-off trivial memories fade in days. The user doesn't have to manage this — the system learns what matters from how it's used.
The SIMPLE Model: Logarithmic Time Compression
One more cognitive science model deserves attention: the SIMPLE model (Brown, Neath & Chater, 2007). SIMPLE proposes that human memory operates on a logarithmically compressed timescale — distant memories feel "closer together" than recent ones do.
The practical implication: apply log(1 + age) to the age before computing decay. The transformed age compresses long timescales while preserving distinctness in recent ones. Two memories from yesterday and the day before remain distinguishable; two memories from 5 years and 6 years ago compress into roughly the same effective age.
This matches a real phenomenon — the further back you go, the harder it is to place events precisely in time. Combining logarithmic compression with power-law decay produces a model that's empirically validated against multiple decades of memory research and behaves correctly across timescales an agent might actually encounter.
When Memory Decay Goes Wrong
Decay is an optimization. Like all optimizations, it has failure modes worth knowing before you ship it.
Tuning the decay rate is domain-specific. A coding assistant where users return to the same project for months needs slow decay. A customer support agent handling unrelated tickets benefits from faster decay so old context doesn't leak into new conversations. A single global decay rate is always wrong for at least one of these — production systems need per-deployment or per-domain calibration against real usage data.
Decay can fight against consolidation. If your system aggressively decays memories before consolidation can run, the consolidated summaries inherit the staleness. Decay should be applied at retrieval time, not at storage time — that way consolidation has access to all the original content even after raw memories have decayed past usefulness.
Half-life confusion. Engineers used to thinking in terms of half-life often misconfigure power-law decay because the math doesn't have a clean half-life concept. The "scale parameter S" in power-law decay is interpretable, but it's not the half-life. Mixing up these parameters is one of the most common bugs — a system that "feels off" but produces no obvious errors.
Cold start problems. A brand-new memory has no retrieval history, so importance can't yet be inferred from frequency. Default importance scoring matters more than people assume. Setting initial importance too high means everything persists; too low means everything decays. The pragmatic answer is medium-default with explicit override — let the API caller pass importance hints when they have them.
Stability tracking has a write cost. Updating per-memory stability on every retrieval adds latency and storage overhead. A typical mitigation is to update stability asynchronously after the query response is returned. The user gets the answer immediately; the stability bookkeeping happens in the background.
How MetaMemory Implements Memory Decay
MetaMemory's temporal layer combines the techniques above into a single coherent system, exposed through configuration rather than hard-coded behavior.
Multiple decay functions, configurable per deployment. The system supports exponential, power-law, and logarithmically-compressed variants. Each deployment picks the function that matches its usage pattern — fast-turnover applications use exponential, long-running applications use power-law, applications spanning years use power-law with logarithmic compression. The default for new deployments is power-law, on the basis that it produces the fewest surprises across the widest range of use cases.
FSRS-inspired stability tracking. Every memory has a tracked stability that updates when the memory is retrieved. Stability gain follows the desirable difficulty principle — memories successfully recalled when their retrievability was already low get larger gains than easy recalls. Difficulty is tracked separately as a per-memory parameter that can be set explicitly or inferred from content characteristics.
Importance-weighted decay rate. The decay scale for each memory is modulated by its importance score, with importance derived from emotional valence, explicit flagging, and retrieval frequency. High-importance memories effectively decay slower; low-importance memories decay at the baseline rate. The user doesn't have to think about this — the system learns from usage.
Decay applied at retrieval, not storage. Memories are stored without decay applied. The decay multiplier is computed at query time based on age and importance. This preserves the original content for consolidation, allows decay parameters to be tuned without re-ingesting data, and keeps the storage layer simple.
Trade-offs
Memory decay isn't free. The costs are worth knowing before you build it:
- Parameter tuning is empirical, not theoretical. No analytical method tells you the right decay rate for your workload. You measure retrieval quality on real queries, adjust, measure again. Plan for at least one round of tuning per major use case.
- Stability tracking adds storage. Every memory needs a stability record, updated on access. For large memory stores, this is a non-trivial cost. The standard mitigation is keeping stability records in a fast cache layer separate from the primary memory storage.
- Importance scoring is only as good as its signals. If your application doesn't expose ways for users to flag importance, and your conversation patterns don't generate clear emotional or frequency signals, importance-weighted decay reduces to ordinary decay. The signals matter.
- Power-law decay is computationally heavier than exponential. Not by much — both are constant-time operations — but at retrieval volumes of millions of memories per second, the difference shows up in profiling. For most production workloads it's irrelevant; for very high-throughput systems it's worth measuring.
Conclusion
Memory decay in AI agents is one of those design decisions that looks trivial from the outside and compounds badly when done wrong. Exponential decay is the default because the math is simple, but it doesn't match how human memory actually works — and over multi-month timescales, the gap between "what your agent retrieves" and "what the user expects to be remembered" widens until the system feels broken even though every individual component works.
Power-law decay, FSRS-inspired stability tracking, and importance-weighted scaling are the three components that make decay actually useful at scale. They're well-validated by decades of cognitive science research and millions of real-world spaced repetition events. The math is more complex than exponential, but the failure modes are more forgiving and the long-term behavior is dramatically more correct.
The agent memory systems that age well will be the ones built on memory models that match how memory actually works. Everything else will get progressively stranger as users accumulate history.