Graph memory in AI agents is the retrieval layer that finds memories by relationship, not similarity. Vector search answers "what's semantically close to this query?" Graph memory answers "what's connected to this entity, and how?" These are different questions with different answers, and most agent memory systems only answer the first one.
Consider a simple example. A user mentions their manager asked them to fix authentication. Later, they mention authentication uses JWTs. Later still, they mention JWTs have a refresh token bug. Vector search can find each memory individually if you ask the right query. But ask "what's the chain of events that led to the refresh token bug?" and vector search has no answer — because the chain is a graph, not a similarity score.
This post covers the mechanics of graph memory in AI agents that most implementations skip: how entities get extracted from conversations, why relationship types matter more than edges alone, how graph traversal actually scores results at query time, and when graph memory makes things worse instead of better.
Assumed audience: Engineers adding memory to AI agents who've already implemented vector search and hit its limits. If you've read our posts on semantic memory, episodic memory, and consolidation, this is the retrieval channel that handles what those can't.
Entity Extraction: Building the Graph from Conversations
Before you can query a graph, you need one. In agent memory, the graph is built incrementally from every conversation — entities are extracted, relationships are inferred, and the graph grows with each interaction.
Entity extraction is the first step, and the one most implementations get wrong by making it too simple or too complex.
The two-tier approach that works in practice: Use an LLM as the primary extractor with a regex-based fallback. The LLM handles nuanced extraction — understanding that "my manager Sarah" contains a person entity with a role relationship. The regex fallback catches structured entities the LLM might miss — ISO dates, organization suffixes (Corp, Inc, LLC), and obvious proper nouns.
Entity types worth extracting: person, organization, location, event, date, concept, product. Seven types cover the vast majority of conversational entities. Going broader (adding "emotion", "skill", "metric") sounds thorough but increases extraction noise faster than it increases retrieval quality.
The extraction prompt matters more than the model. A prompt that returns structured JSON with entity name, type, aliases, and confidence score gives you everything needed for downstream linking. Low temperature (0.2 or below) is critical — you want consistent, deterministic extractions, not creative interpretations of what constitutes an entity.
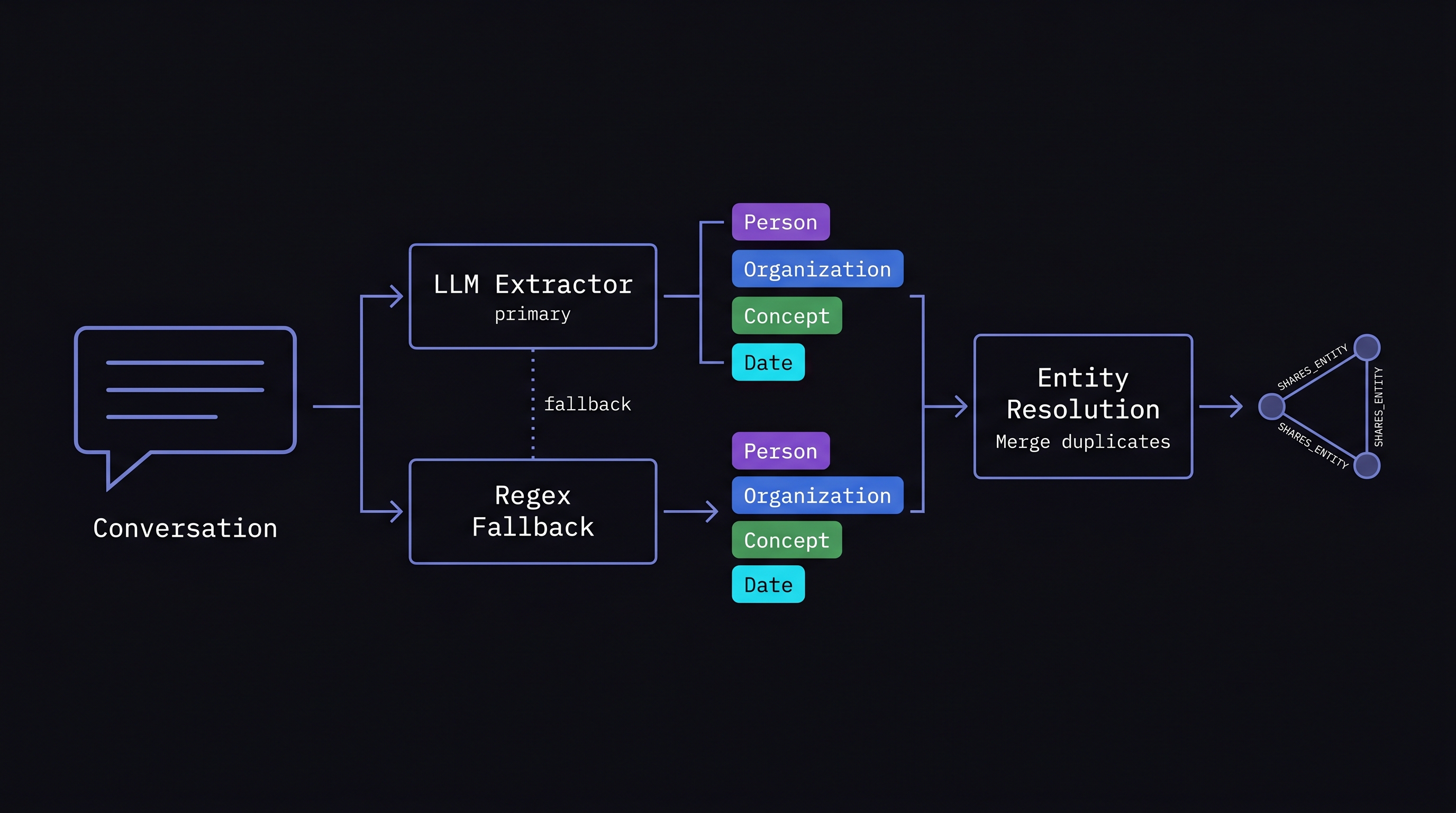
The hard part is entity resolution. "Sarah", "my manager", "Sarah Chen", and "the PM" might all be the same person. Without resolution, your graph has four disconnected nodes instead of one well-connected one. Resolution requires comparing new entities against existing ones by name similarity, alias matching, and co-occurrence patterns. This is where most graph memory implementations silently degrade — they extract entities fine but never merge the duplicates.
Why Relationship Types Matter More Than Edges
A graph with untyped edges — just "A is connected to B" — is barely more useful than a list. The value of graph memory comes from typed relationships that encode how things are connected.
Eight relationship types cover the core patterns in agent memory:
- CAUSED_BY — causal chains. "The outage was caused by the rate limit." Enables "what caused X?" queries.
- LEADS_TO — sequential progression. "The auth migration leads to the token refresh implementation." Enables forward traversal through processes.
- SIMILAR_TO — semantic similarity between memories, stored as a graph edge rather than just a vector score. Bidirectional. Enables "what else is like this?" without a vector query.
- CONSOLIDATED_FROM — links a consolidated memory to its sources. Enables drill-down from summaries to originals.
- IN_SAME_EPISODE — temporal co-location. Two memories from the same session/episode. Enables "what else happened in that conversation?"
- EMOTIONAL_TRANSITION — tracks emotional state changes. "Frustrated → relieved" across memories about the same topic. Enables "when did the user's mood change about X?"
- PROCESS_SEQUENCE — workflow steps. "Step 1 → Step 2 → Step 3" of a process the user described. Enables "what's the next step?"
- SHARES_ENTITY — two memories mention the same entity. Created automatically during entity linking. The most common edge type and the backbone of multi-hop traversal.
The SHARES_ENTITY type deserves special attention. When a new memory is created and entities are extracted, the system automatically finds other memories mentioning the same entities and creates edges between them. This means the graph grows passively — no explicit relationship extraction needed for the most common connection type. The user mentions "Stripe API" in a debugging conversation and again in an architecture discussion; the graph connects them automatically.
The relationship type determines traversal behavior. Causal edges (CAUSED_BY, LEADS_TO) should propagate activation strongly — if you're looking for what caused something, the causal chain is the signal. Co-location edges (IN_SAME_EPISODE) should propagate weaker — sharing a session is contextual, not causal. Typing your edges is what makes traversal produce ranked, meaningful results instead of a flat list of "connected stuff."
Graph Traversal: How Retrieval Actually Works
At query time, graph memory doesn't scan the entire graph. It starts from a small set of seed nodes and spreads outward, decaying activation at each hop.
The algorithm is spreading activation — borrowed from cognitive science (Collins & Loftus, 1975), where it models how activating one concept in human memory spreads to related concepts with decreasing intensity.
The process has four steps:
Step 1: Seed selection. Extract entities from the user's query. Find memories that mention those entities. These are your seed nodes — the starting points for traversal. If entity extraction finds nothing (vague query, no named entities), fall back to the top semantic search results as seeds. This fallback is important: it means graph retrieval degrades gracefully to vector-augmented traversal rather than returning nothing.
Step 2: Activation spread. From each seed node (activation = 1.0), traverse outgoing edges to neighboring nodes. Each neighbor receives activation equal to the source's activation multiplied by a decay factor and a link-type multiplier. CAUSED_BY and SHARES_ENTITY edges carry activation strongly. IN_SAME_EPISODE carries less. The decay factor ensures activation drops with each hop — typically losing 30-50% per hop.
Step 3: Pruning. Stop traversing from any node whose activation falls below a minimum threshold. This prevents the search from degenerating into a full graph scan on densely connected subgraphs. A typical depth limit of 2-3 hops combined with the activation threshold keeps traversal fast and focused.
Step 4: Scoring and return. Collect all activated nodes, sort by activation score, exclude the seeds (the user already knows what they asked about), and return the top results. Each result carries an explanation: "Reached via 2 hops through SHARES_ENTITY → CAUSED_BY" — which gives the agent context about why this memory is relevant, not just that it is.
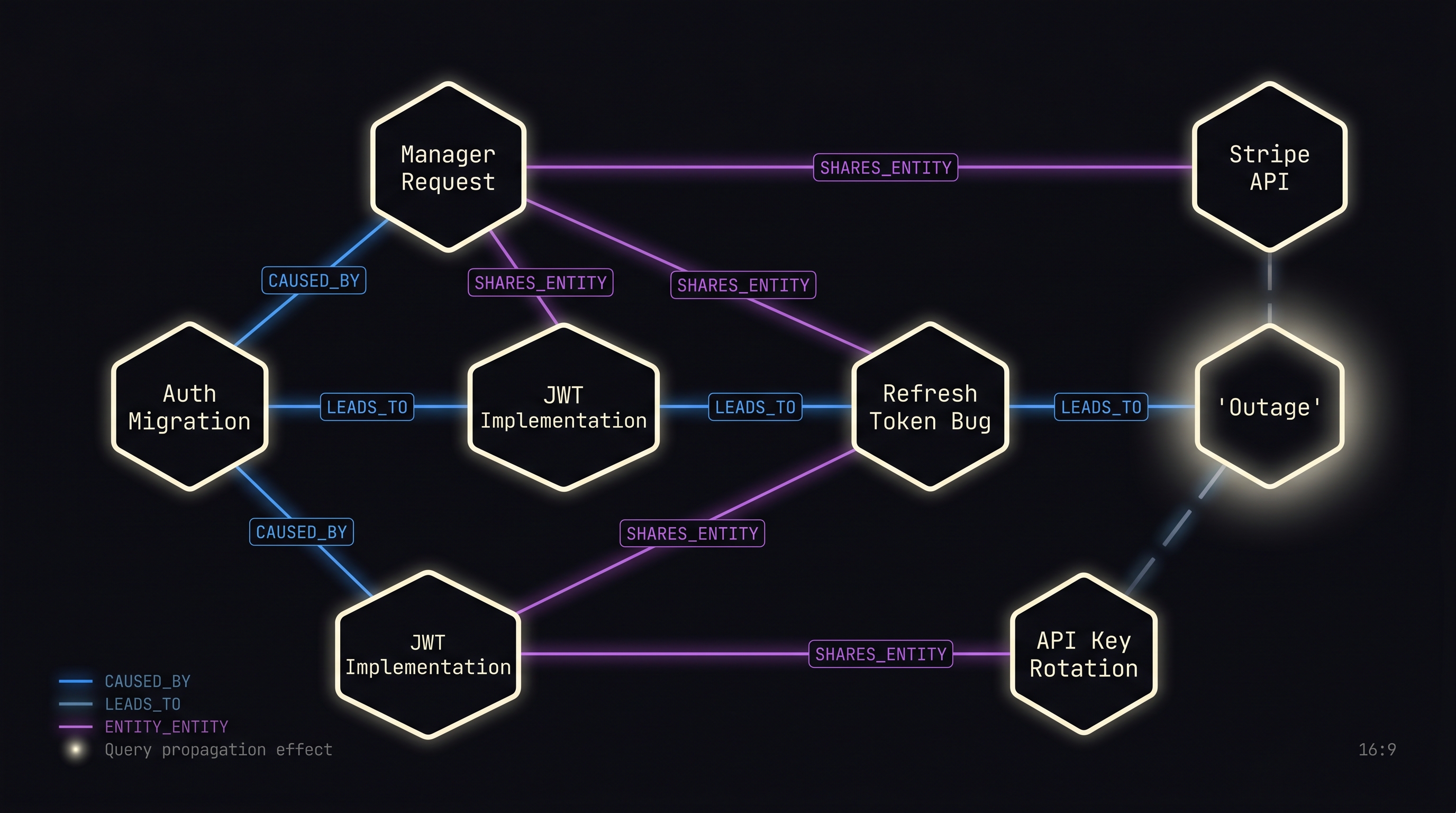
The key insight: spreading activation finds memories that are structurally close in the relationship graph, not semantically similar in vector space. "JWT refresh token bug" and "manager's request to fix auth" are not semantically similar — they share almost no words. But they're 2 hops apart in the relationship graph. Vector search misses this. Graph traversal finds it.
Graph + Vector Hybrid: Why You Need Both
Graph memory doesn't replace vector search. It answers a different class of queries that vector search structurally can't handle.
The queries that each channel wins on:
- Vector wins: "What did we discuss about authentication?" — semantic similarity is the right signal. The user wants content-similar memories, and cosine similarity delivers exactly that.
- Graph wins: "What caused the outage last Tuesday?" — causal chain traversal. The answer is connected to the query through relationships, not through shared vocabulary.
- Both needed: "What was the context around the auth migration?" — semantic retrieval finds auth-related memories, graph retrieval finds memories connected to the migration through entity and causal links. The union of both result sets gives a more complete answer than either alone.
Fusing results from multiple channels requires a ranking algorithm that normalizes scores across different scales. Reciprocal Rank Fusion (RRF) is the standard approach: instead of comparing raw scores (which are incomparable across channels), compare ranks. A memory ranked #1 by the graph channel and #5 by the semantic channel gets a fused score that reflects its relevance across both perspectives.
The fusion formula: RRF(d) = Σ_c [w_c / (k + rank_c(d))] where w_c is the channel weight, k is a smoothing constant (typically 60), and rank_c(d) is the memory's rank in channel c. Channel weights can vary by query type — multi-hop queries should weight the graph channel higher, while factual recall queries should weight semantic higher.
When Graph Memory in AI Agents Fails
Graph memory introduces failure modes that vector-only systems don't have. Understanding these is critical before you add a graph layer.
Entity extraction accuracy compounds. Every entity the extractor gets wrong — a false positive, a missed entity, a wrong type classification — creates bad nodes and edges in the graph. Unlike vector search where a bad embedding just means slightly worse similarity scores, a bad graph edge means traversal can follow completely wrong paths. If "Python" is extracted as a location instead of a concept, every query about your Python project will traverse through geography nodes. The error compounds because future memories link to the wrong entity.
Entity resolution is an unsolved problem at scale. "Sarah", "S. Chen", "the PM", "my manager" — humans resolve these trivially from context. Automated resolution requires maintaining an entity catalog, comparing new extractions against it on every memory creation, and making merge decisions that are hard to reverse if wrong. At small scale (hundreds of memories), this is manageable. At large scale (millions of memories across thousands of users), entity resolution becomes a significant infrastructure challenge with no clean solution.
Dense graphs become useless. If every memory is connected to every other memory through 2-3 hops (common in long-running conversations about a single project), spreading activation activates the entire subgraph. Everything scores similarly, nothing stands out. The graph effectively degenerates into a flat list. The fix is aggressive relationship pruning — only create edges above a confidence threshold, and periodically garbage-collect low-weight edges that add noise without adding retrieval value.
Write latency on every memory creation. Entity extraction, resolution, linking, and graph edge creation all happen when a new memory is stored. This adds 200-500ms of processing per memory on top of the vector embedding. For real-time conversational agents, this latency is noticeable. Running entity extraction asynchronously (fire-and-forget) solves the user-facing latency but means the graph isn't immediately queryable for the most recent memory.
How MetaMemory Implements Graph Memory
MetaMemory's graph channel is one of five retrieval channels in the fused retrieval system, with query-type-dependent weighting — multi-hop queries weight the graph channel highest, while general queries weight semantic highest.
Two-tier entity extraction. The primary extractor uses an LLM at low temperature for nuanced entity recognition across seven types: person, organization, location, event, date, concept, and product. A regex-based fallback catches structured patterns the LLM misses — dates, organization suffixes, and proper nouns. Extraction runs asynchronously after memory creation to avoid blocking the write path.
Eight typed relationships. Every edge in the graph has a type that determines traversal behavior: causal edges (CAUSED_BY, LEADS_TO) propagate activation strongly, co-location edges (IN_SAME_EPISODE) propagate weaker, and entity-sharing edges (SHARES_ENTITY) are created automatically during entity linking — forming the backbone of the graph without explicit relationship extraction.
Spreading activation traversal. At query time, entities are extracted from the query to identify seed memories. Activation spreads from seeds through the graph with per-hop decay and link-type-specific multipliers. Traversal is depth-limited and pruned by a minimum activation threshold to keep it fast. Results merge with the other four channels via Reciprocal Rank Fusion.
Neo4j for graph storage. All graph operations — node creation, edge creation, traversal, pattern matching — run against Neo4j. Entity-memory linkages are stored in PostgreSQL for fast lookup during seed selection. This dual-storage approach lets each database do what it's best at: PostgreSQL for relational queries and Neo4j for graph traversal.
Trade-offs
- Infrastructure complexity. Graph memory requires a separate database (Neo4j, Amazon Neptune, or equivalent) alongside your vector store and relational database. That's three storage systems to maintain, monitor, and scale. For small-scale agents with simple memory needs, this complexity isn't justified.
- Entity extraction cost. Every memory creation triggers an LLM call for entity extraction. At scale, this is a meaningful cost — both in latency and in API spend. The regex fallback reduces LLM calls for obviously structured entities, but the LLM remains necessary for nuanced extraction.
- Graph maintenance. Graphs accumulate noise over time. Low-confidence edges, duplicate entities, and orphaned nodes degrade traversal quality. Periodic cleanup — pruning weak edges, merging duplicate entities, removing orphaned nodes — is required, and there's no standard tooling for it.
- Diminishing returns on simple queries. For straightforward recall ("what did we discuss about X?"), graph traversal adds latency without improving results. The graph channel's value is concentrated in multi-hop, causal, and relationship queries. If your agent rarely receives those query types, graph memory is overhead.
Conclusion
Graph memory in AI agents fills the gap that vector search leaves open: relationships between memories. Entity extraction builds the graph from conversations, typed relationships encode how things connect, and spreading activation traverses those connections at query time with decaying intensity.
The value is real but narrow. Graph memory shines on multi-hop queries, causal chains, and entity-based lookups. It adds nothing on simple semantic recall. Building it requires entity extraction infrastructure, a graph database, and ongoing graph maintenance. The decision to add graph memory should be driven by whether your users ask relationship questions — not by whether graph databases are technically interesting.
Further Reading
- Memory Decay in AI Agents: Why Exponential Forgetting Fails
- What Is Semantic Memory in AI Agents? A Technical Deep Dive
- Episodic Memory in AI Agents: Sessions, Decay, and Continuity
- Memory Consolidation in AI Agents: Why Storing Everything Fails
- Most RAG Systems Use One Channel. We Use Five. Here's Why.
- Docs: Multi-Vector Encoding