Memory consolidation in AI agents is the process of merging, compressing, and resolving redundant or contradictory memories to keep the memory store useful as it grows. Most agent memory tutorials focus on how to store and retrieve. Few discuss what happens six months later when your agent has 50,000 memories and retrieval quality is worse than when it had 500.
The problem isn't storage — it's noise. As memory accumulates, similar memories cluster together, outdated information coexists with corrections, and retrieval becomes a lottery of near-duplicates competing for relevance. Memory consolidation in AI agents is the maintenance layer that prevents this degradation.
This post covers the mechanics that most implementations skip: when consolidation should trigger, the trade-off between deduplication and summarization, how to handle contradicting memories without losing context, and the failure modes that make consolidation itself a source of errors.
Assumed audience: Engineers building persistent memory for AI agents. If you've read our posts on semantic memory and episodic memory, this is the next layer — what happens after your memory store is populated.
Why Storing Everything Fails
The intuition is that more memory is better. It isn't.
Consider an agent that's had 200 conversations with a user about authentication. The user's approach evolved: started with session tokens, switched to JWTs in week 3, hit a refresh token bug in week 5, resolved it in week 6. The memory store has hundreds of entries about authentication — many saying similar things, some contradicting others, all ranked by cosine similarity at retrieval time.
When the user asks "what's our auth approach?" the agent retrieves the top-k most similar memories. But similar to what? The query is semantically close to all 200 auth memories. The top results might include the week-1 session token approach alongside the week-6 JWT resolution. The agent has no way to know which is current.
This is the retrieval degradation problem: as memory grows, the signal-to-noise ratio drops. More memories means more candidates competing for the same retrieval slots, and cosine similarity alone can't distinguish current from obsolete.
Consolidation solves this by reducing the memory set to its essential, non-redundant, temporally coherent core.
When to Trigger Consolidation
Most tutorials say "consolidate after each session." That's one option, and often the wrong one for production systems.
Three trigger strategies, each with different trade-offs:
Post-session consolidation. Run consolidation when a session ends. The advantage is predictable timing — you know exactly when it fires. The disadvantage: sessions vary wildly in length and content. A 2-minute session that added one memory doesn't need consolidation. A 90-minute deep technical session that added 40 memories does. Fixed timing ignores the actual state of the memory store.
Memory pressure triggers. Consolidate when the unconsolidated memory count exceeds a threshold — say, 50 or 100 new memories since the last consolidation. This is more responsive to actual memory growth. The downside: it can fire mid-session if the user is in a long conversation, introducing latency at the wrong moment. Async background processing mitigates this but means the consolidated view isn't immediately available.
Query-time consolidation. When a retrieval query returns too many near-duplicate results, trigger consolidation on that cluster before returning results. This is the most targeted approach — you only consolidate what's actively causing retrieval problems. The downside: it adds latency to the query path, which is the most latency-sensitive part of the system.
A practical approach combines these: post-session for routine maintenance, memory pressure for high-volume sessions, and query-time as a last resort for clusters that slipped through. Priority ordering matters — don't consolidate synchronously on the query path if background consolidation can catch it first.
The Deduplication-Summarization Spectrum
This is the decision most implementations get wrong because they treat it as binary: either merge duplicates or summarize everything. In practice, it's a spectrum.
Pure deduplication identifies memories that say nearly the same thing and keeps one. "User prefers dark mode" and "The user likes dark mode for their IDE" are duplicates — keep whichever has more context, discard the other. This is safe, lossless, and easy to implement. The trigger is high cosine similarity — typically 0.85 or above.
Pure summarization takes a cluster of related memories and compresses them into a single summary via an LLM. Ten memories about authentication debugging become one paragraph covering the key decisions and outcomes. This achieves much higher compression but is lossy — specific details that seemed unimportant to the summarizer may have been important to the user.
The middle ground is what actually works: dedup first, then summarize clusters that remain too large.
Start by removing near-duplicates above a high similarity threshold. What remains is a set of genuinely distinct memories on similar topics. If that set is still large (say, more than 5-7 memories on the same topic), summarize it — but keep the original memories accessible for granular retrieval. The summary serves as a high-level index; the originals serve as the detail layer.
The critical question is where on the spectrum to operate for each cluster. Memories about user preferences are safe to summarize aggressively — "prefers dark mode, uses VS Code, writes TypeScript" doesn't need 15 separate entries. Memories about debugging sessions should be summarized cautiously — the specific error code from session 7 might be the exact detail the user asks about later.
How Memory Consolidation Actually Works
The consolidation pipeline has four stages.
Stage 1: Candidate identification. Group unconsolidated memories by semantic similarity. For each memory, find all other memories with cosine similarity above the threshold. Form clusters from these groups. A memory can only belong to one cluster — assign it to the cluster where it has the highest average similarity.
Stage 2: Cluster classification. For each cluster, determine the appropriate merge strategy. Pure duplicates (similarity > 0.9) can be deduplicated without an LLM call. Topically related memories (similarity 0.85-0.9) need LLM-powered summarization. Memories below the threshold stay unconsolidated.
Stage 3: LLM consolidation. For clusters that need summarization, pass the memories to an LLM with a consolidation prompt. The prompt instructs the model to combine overlapping information, preserve unique insights, maintain chronological context, and keep emotional states. Low temperature (0.2-0.3) is critical — you want factual, deterministic output, not creative rewriting.
Stage 4: Metadata merge. The consolidated memory inherits metadata from its sources: the union of all topics, the union of all emotional tags (with averaged intensities), and a reference to all original memory IDs. This reference is what allows drill-down from a summary back to the original turns if needed.
Compression targets vary, but a 70% reduction (keeping 30% of the original token count) is a reasonable starting point. The actual compression ratio should be measured and logged for each consolidation — if the LLM consistently produces output that's 80% of the original, the prompt isn't compressing enough.
When Memories Contradict Each Other
This is the problem most consolidation systems ignore entirely. It's also the one that causes the most visible failures.
"User's auth approach is session tokens" (from week 1) and "User switched to JWTs" (from week 3) aren't duplicates — they're a temporal progression. Merging them into a single memory loses the evolution. Keeping both without context means the agent might reference the outdated approach.
Five types of temporal relations between memories, each requiring a different merge strategy:
- Supersedes — the new memory completely replaces the old. "We use JWTs now" supersedes "We use session tokens." The old memory should be marked with a validity end date, not deleted — you may need it for "what did we use before?" queries.
- Supplements — the new memory adds to the old without contradicting it. "We added refresh token rotation" supplements "We use JWTs." Both remain valid.
- Contradicts — the facts are incompatible and can't both be true at the same time. This needs investigation — which is more recent? Is there context that resolves the contradiction?
- Refines — the new memory is a more precise version of the old. "We use RS256 JWTs with 15-minute expiry" refines "We use JWTs." The refined version replaces the vague one.
- Reverts — the new memory returns to a state described by an even older memory. "We switched back to session tokens" reverts the JWT adoption. The full chain of changes matters for context.
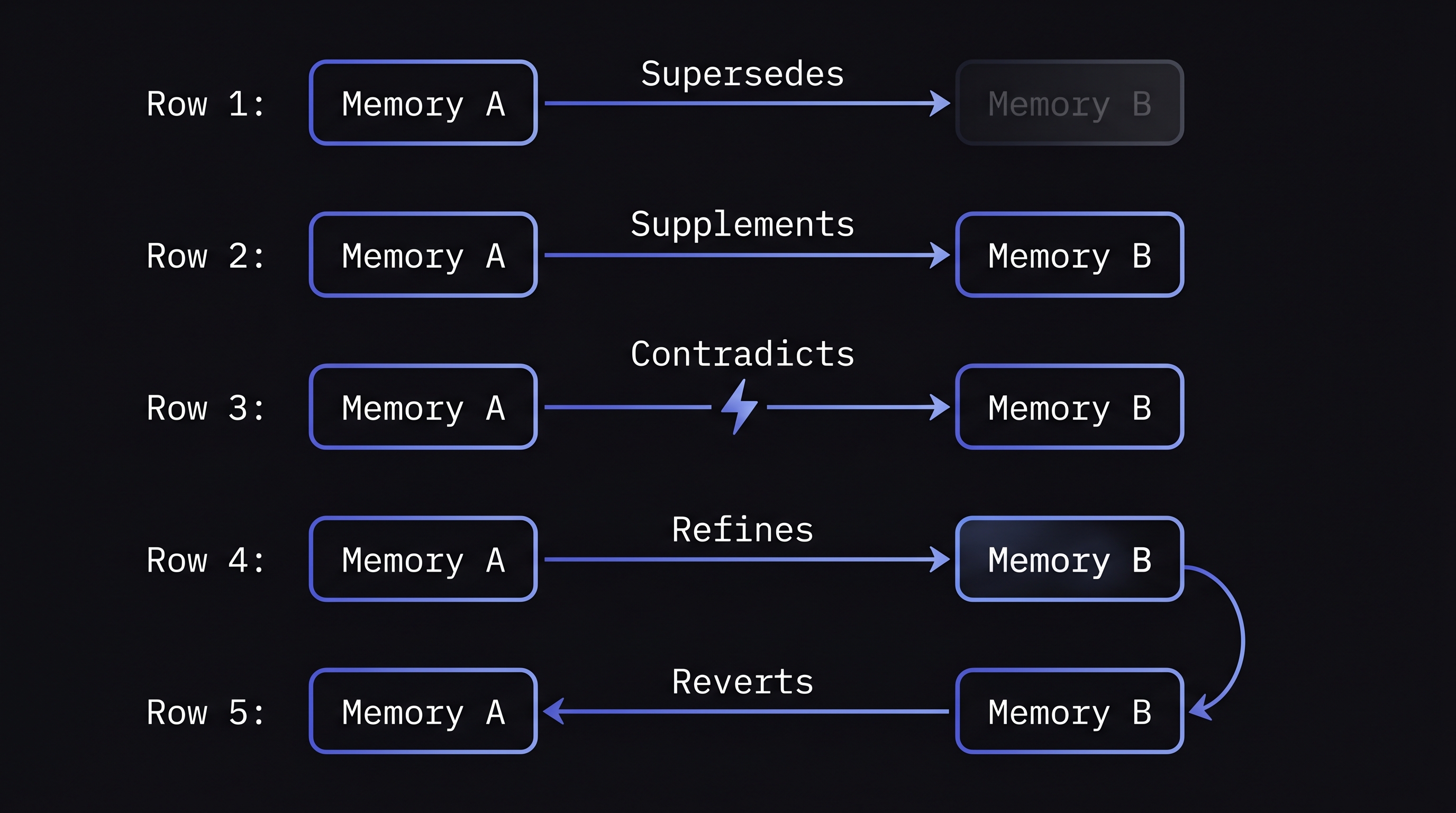
Classifying these relations automatically requires an LLM call that compares pairs of memories with their timestamps. The classification should be done at very low temperature for consistency, with a fallback to "supplements" (the safest default — it preserves both memories) when classification confidence is low.
The underlying data model that makes this work is bi-temporal storage: every memory has two time dimensions. Validity time — when the fact was true in the real world. System time — when the system learned about it. This enables queries like "what was true about our auth approach on March 15?" even if the system didn't learn about the change until March 20.
When Consolidation Goes Wrong
Consolidation is an optimization. Like all optimizations, it introduces its own failure modes.
Summary hallucination. The LLM generating the consolidated summary invents details that weren't in any source memory. A debugging session about "JWT refresh token expiry" might get summarized as "JWT refresh token expiry set to 24 hours" when no specific duration was mentioned. Low temperature reduces this but doesn't eliminate it. The fix: compare the consolidated output against source memories and flag any claims that can't be traced back to a source.
Over-compression. Aggressive compression targets (90%+ reduction) lose details that seemed unimportant at consolidation time but become critical later. The user asks about a specific error code that was mentioned once in a 40-message session — the consolidation kept the resolution but dropped the error code. The fix: keep original memories accessible as a detail layer behind the summary, and tune compression targets conservatively (70% reduction is aggressive enough for most use cases).
Temporal context loss. Summarizing a sequence of events into a paragraph loses the ordering and timing information. "User debugged auth, switched from sessions to JWTs, encountered refresh bug, fixed it" is chronological. The summary might restructure this by topic rather than time, losing the narrative arc. The fix: the consolidation prompt should explicitly instruct the LLM to preserve chronological ordering.
Emotional flattening. A user who was frustrated during debugging and relieved after fixing the issue has two distinct emotional states associated with the same topic. Summarizing the memories can flatten this into a neutral summary that captures neither emotion. The fix: preserve emotional metadata separately from the text content — emotions should be merged as structured data (averaged intensity, union of tags), not left to the LLM to summarize in prose.
How MetaMemory Implements Memory Consolidation
MetaMemory's consolidation pipeline implements the concepts above with specific design decisions.
Similarity-triggered grouping. Unconsolidated memories are grouped by cosine similarity above a configurable threshold. Groups of two or more memories are candidates for consolidation. Each consolidation batch is capped to prevent runaway LLM costs on large clusters.
LLM-powered summarization with emotional preservation. The consolidation prompt instructs the model to combine overlapping information while preserving unique insights, chronological context, and emotional states. Emotional metadata from source memories is merged separately as structured data — intensities are averaged, emotion labels are unioned — ensuring emotional context survives even if the LLM's prose summary flattens it.
Temporal relation analysis. When two memories potentially conflict, MetaMemory classifies the relationship using the five-type model: supersedes, supplements, contradicts, refines, or reverts. Memories that supersede or contradict older ones are handled through a bi-temporal model that records both when a fact was true in the world and when the system learned about it. Old memories aren't deleted — they're marked with a validity end date so temporal queries still work.
Originals preserved. Consolidated memories store references to their source memory IDs. The originals remain in the store for granular retrieval — the consolidated summary serves as a high-level entry point, not a replacement. This is the safety net against over-compression: if the summary lost a detail, the original is still there.
Trade-offs
Memory consolidation is not free. The costs are worth knowing before you build it:
- LLM cost per consolidation. Every summarization is an LLM call. For a system with thousands of users and regular consolidation cycles, this becomes a meaningful cost line. Batch consolidation and dedup-before-summarize both reduce the number of LLM calls, but the cost scales with memory volume regardless.
- Information loss is irreversible if originals aren't kept. If you delete source memories after consolidation, any detail the LLM dropped is gone forever. Keeping originals doubles storage but preserves the ability to re-consolidate with better prompts or models later.
- Consolidation quality depends on LLM quality. The same trade-off as session summaries in episodic memory: smaller, cheaper models produce worse consolidations. A consolidation that merges two important nuances into a vague generalization is worse than no consolidation at all.
- Threshold tuning is domain-specific. A similarity threshold that works for conversational memory may be too aggressive for technical documentation or too conservative for casual chat. Every deployment needs calibration against real data.
Conclusion
Memory consolidation in AI agents is the maintenance layer between storage and retrieval. Without it, memory stores degrade over time — more entries means more noise, more near-duplicates competing for retrieval slots, and more outdated information coexisting with current facts.
The mechanics require similarity-based grouping, a strategy that ranges from deduplication to summarization depending on the cluster, temporal relation analysis for contradicting memories, and careful preservation of emotional and chronological context through the merge process. Getting these right is the difference between an agent whose memory gets sharper over time and one whose memory gets noisier.
Further Reading
- Memory Decay in AI Agents: Why Exponential Forgetting Fails
- Graph Memory in AI Agents: How Relationships Change Retrieval
- What Is Semantic Memory in AI Agents? A Technical Deep Dive
- Episodic Memory in AI Agents: Sessions, Decay, and Continuity
- Most RAG Systems Use One Channel. We Use Five. Here's Why.
- Docs: Multi-Vector Encoding
- Docs: Episode Tracking